LLaVA,作为最早一批出现的多模态大模型,其模型结构与训练策略对于现在的多模态模型发展产生了巨大的影响。因此,我们将在本期内容中聊一聊 LLaVA 系列,希望对大家有所帮助。
LLaVA
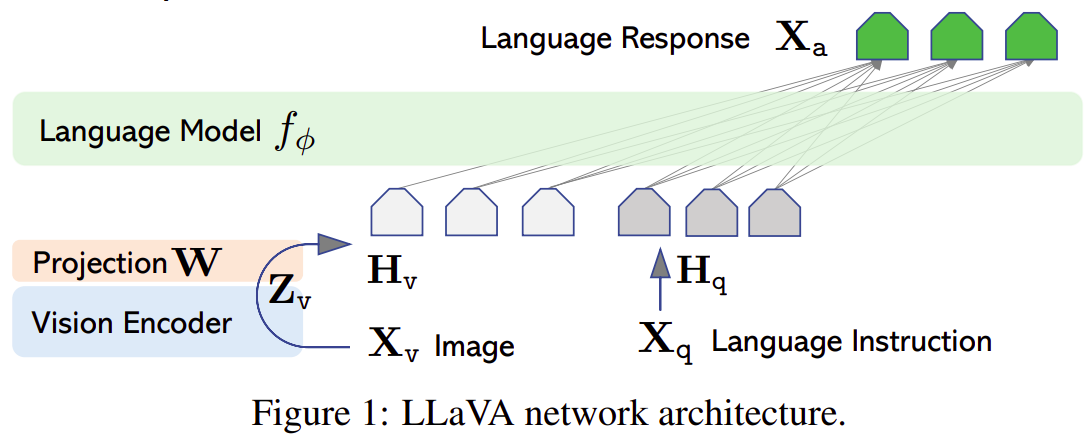
LLaVA 1 模型的架构如上图所示,其包含一个 Vision Encoder 模块,负责提取图片特征;一个 Projection,负责将图片特征映射到 LLM 可接受的特征空间;以及一个 LLM 负责处理输入,并生成相应的语言模态的输出。
在推理时,图片会依次经过 Vision Encoder 的编码以及 Projection 的特征转换,并与经过 tokenizer 和 embedding 层的 instruction 进行拼接,作为 LLM decoder layer 的输入,从而进行 LLM 的前向过程。某种意义上讲,Vision Encoder 和 Projection 所扮演的角色等价于视觉的 tokenizer + embedding 层。
LLaVA 的训练分为两个阶段,第一阶段为特征对齐阶段,冻结 Vision Encoder 与 LLM,只开放 Projection 的训练,从而让 Projection 模块学习到特征映射关系。第二阶段为端到端微调过程,只冻结 Vision Encoder,开放 Projection 与 LLM 的训练,从而实现多模态的对话。
更具体地,Vision Encoder 方面选用了 CLIP-ViT-Large-Patch14(输入大小为 224px),LLM 方面选用了 Vicuna(基于 LLaMA 使用 ShareGPT 数据微调得到),Projection 仅为一个线性层。
LLaVA-1.5
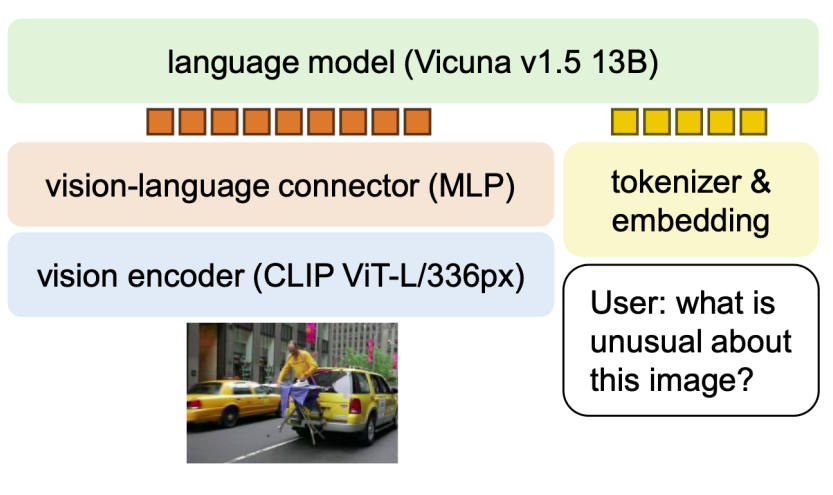
相较于 LLaVA,LLaVA-1.5 2 在数据和模型方面进行了进一步扩展,从而在模型表现方面取得了进一步的提升。
模型方面,LLaVA-1.5 将 Projection 由线性层更换为了一个两层的 MLP,将 Vision Encoder 更换为了 CLIP-ViT-Large-Patch14-336px。
数据方面,LLaVA-1.5 加入了特定任务的数据集,以强化模型的表现。加入的数据集包括 VQA、OCR 以及区域感知数据。
此外,通过进一步增大输入图像大小,并应用 AnyRes 技术,LLaVA-1.5-HD 将 LLaVA-1.5 扩展到了更高的分辨率。但 AnyRes 技术并未直接应用于 LLaVA-1.5,而是应用于后续的 LLaVA-NeXT,因此动态分辨率技术将在 LLaVA-NeXT 中进行介绍。
LLaVA-NeXT
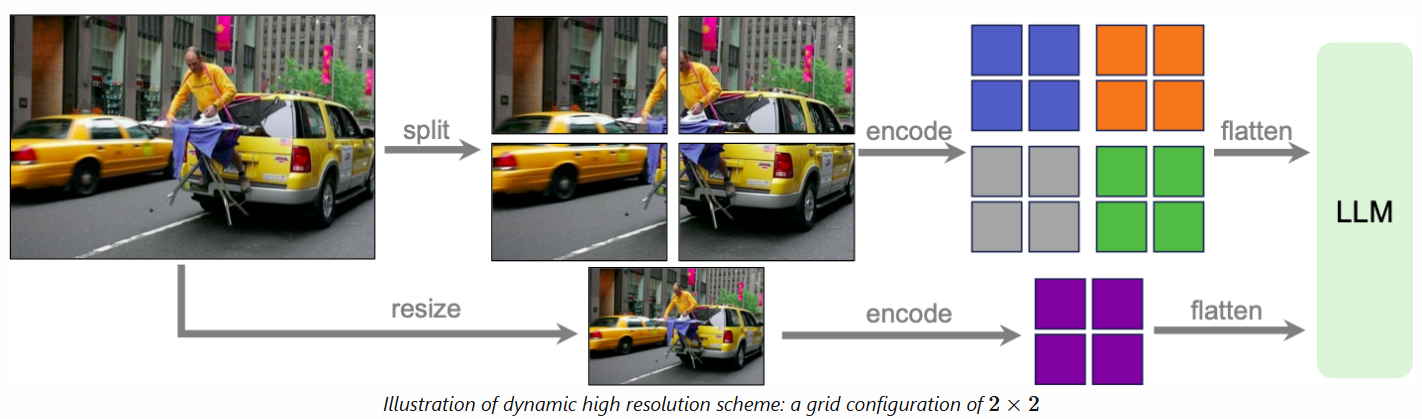
最后是 LLaVA-NeXT 3,其进一步支持了高分辨率图像。它支持三种宽高比,分别为 672x672,336x1344,1344x336。(Vision Encoder 的输入是 336px)使用 Hermes-Yi-34B 为 LLM 的 LLaVA-NeXT 更是在多项评测标准上超过了 Gemini-Pro。
此外,LLaVA-NeXT 真正应用了 AnyRes 技术。如上图所示,图片一方面按照 2x2 进行分割并分别编码,最后合并展平,输入给 LLM。另一方面,图片会进行降采样并直接进行编码,从而为 LLM 提供图片的全局信息。分割方式具体包含 2x2,1x2,1x3,1x4,2x1,3x1 和 4x1。
除此之外,LLaVA-NeXT-Video 4 将 AnyRes 技术扩展到视频,将拼接的多个 patch 换为多个 frame。并通过 RoPE 的缩放使得 LLaVA-NeXT 能够处理更长的视频。
在使用了更大的 LLM 后,LLaVA-NeXT 的能力迎来了进一步强化 5。此处的 LLaVA-NeXT 使用了 Qwen1.5-110B、Qwen1.5-72B、LLaMA3-8B 作为 LLM,其中使用了 Qwen1.5-110B 的 LLaVA-NeXT 的模型表现更是直追 GPT4-V。
除了上面的这些,LLaVA 官方仓库还提到了:
-
使用 RLHF(Reinforcement Learning from Human Feedback) 技术来提升模型事实定位能力并减少幻觉的 LLaVA-RLHF 6
-
一个集图像对话、分割、生成与编辑于一体的 Demo,LLaVA-Interactive 7
-
使用外部工具的多模态 Agent,LLaVA-Plus 8
那么,本期内容就到这里了。如有错误,欢迎大家指正!